


2021-10-02: 08:30 – 14:10 CEST
Summary
Millions of users and hundreds of thousands of merchant partners rely on Klarna to be able to shop, pay and bank online and in-store every day. Ensuring that our systems work as planned and avoiding any disturbances is of the utmost importance to us. We have numerous processes and safeguards in place to protect against this. Despite this, on October 2, 2021, we saw disturbances in our systems primarily in Europe, resulting in difficulties for a subset of our consumers and merchants to complete purchases through Klarna.
In this blog post we will share more detailed information on what happened and why, and most importantly, what we can learn from this experience to be able to take all necessary steps to prevent these disturbances from recurring.
The root cause of this incident is detailed below and relates to how our applications (e.g. Klarna Checkout, Klarna Payments) send technical logs. We use these technical logs to ensure that our applications are running as we expect, and they are critical during investigations when things aren’t working correctly. Our applications run on top of what we call a runtime platform. One of the jobs of the runtime platform is to deliver these technical logs to a system which processes technical logs, called the “log-forwarder”.
To summarize what happened, in the Spring of 2021 we made changes to improve
. As part of this, we inadvertently introduced a change in how technical logs are delivered to the log-forwarder. This change did not cause any unexpected behavior for four months until the log-forwarder experienced increased response times due to an unrelated configuration change. The increased response times led many applications deployed on the runtime platform to experience severe service degradation that was difficult to pinpoint as the underlying change causing the disturbances was implemented months earlier.In addition to mitigating the current incident, we have implemented a number of changes to prevent recurrence and reduce the impact of this type of issue, and continue to work on additional safeguards to improve availability.
Timeline
All times CEST
2021-04-26 09:36: We merged runtime platform improvements, which included an inadvertent change to how technical logs were delivered to the log-forwarder.
2021-07-21 14:21: The runtime platform improvements were gradually adopted across the organization.
2021-09-07 16:15: Log-forwarder configuration changed from `drop_newest` to `block`.
2021-10-01 12:55: Log-forwarder configuration changed to enable us to measure the size and cardinality of the technical logs

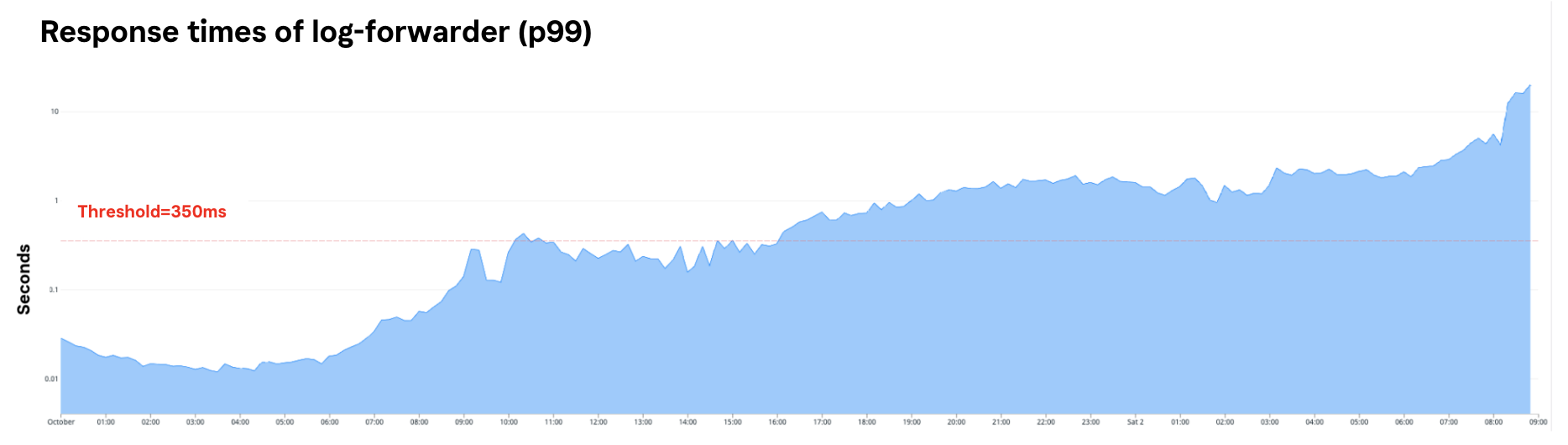
Maximum response time for 99% of requests to log-forwarder 2021-10-01 12:55 – 2021-10-02 08:30
2021-10-02 08:30: We observed the first signs of disturbance to several of our systems, which manifested in the form of increased response times and/or errors. Engineering teams began to investigate and work on fixing and mitigating the disturbance.
2021-10-02 08:56: We observed severe issues in the Klarna Checkout & Klarna Payments.
2021-10-02 09.15-10:19: We escalated the disturbance to a critical level and engaged the Crisis Management Team.
2021-10-02 11:20: We routed Klarna Payments traffic through a different, unaffected system. Klarna Payments started to recover for a large number of merchants, but not at full capacity.
2021-10-02 11:55: We further increased capacity for supporting services for Klarna Checkout. Klarna Checkout returned to normal operation.
2021-10-02 12:02: Klarna Checkout performance degraded severely.
2021-10-02 13:09: We further increased capacity for supporting services for Klarna Checkout. Klarna Checkout performance improved but was still degraded.
2021-10-02 13:40: Klarna Payments performance degraded severely.
2021-10-02 13:41: An alert on log-forwarder was triggered, which sent an automatic page to on-call.
2021-10-02 13:43: Klarna Checkout performance degraded severely.
2021-10-02 14:10: We deployed mitigating changes for log-forwarder.
2021-10-02 14:10: All purchase flows were fully recovered and transacted at full capacity.
2021-10-02 16:17: The Klarna App was fully available again for all consumers.
Root Cause Analysis
On October 2nd, starting around 08:30 CEST, Klarna suffered significant performance degradation across many of our services primarily in Europe. For more information on how this impacted our customers see the
.As soon as we received alerts of issues, we assembled an incident management team that represented all impacted parts of Klarna. Given the impact across many services, we suspected that there was either an issue with one of our critical applications or a networking issue. While multiple teams worked relentlessly on trying to find the root cause, other teams focused on taking mitigating measures to restore service, enabling as many transactions as possible for our consumers and mitigating business impact for our merchants. This included:
Scaling affected services up
Moving merchant traffic from affected services to unaffected services
Disabling the Klarna App for users in Europe to increase capacity for transactions
Regularly restarting critical services that became unavailable
To determine the root cause, we took two tracks:
We identified the least complex yet impacted application and worked in detail to understand the cause of the performance degradation.
We opened a critical incident with our cloud provider to help us analyze potential networking problems.
While testing and ultimately, exhausting these two tracks, we in parallel explored other alternatives. During this analysis work we saw that our log-forwarder dashboards clearly showed an anomaly. The actions we took throughout the rest of the day were based on the now confirmed hypothesis that our log-forwarder was causing the disturbance.
During the analysis work, we identified these are the main drivers for the incident:
When implementing an improved deployment workflow, a Klarna team had inadvertently changed the docker log driver from `non-blocking` to the default `blocking` mode. This change was fully reviewed according to our internal processes, was fully tested and was live for months before the incident. A contributing factor to this was the lack of support for this setting in the cloud vendor tooling used.
A Klarna team had changed the log-forwarder to stop processing when internal buffers in the log-forwarder became overloaded (rather than the previous configuration which would drop logs in this scenario). This was done to gain clear visibility when the log-forwarder was overloaded. The analysis for this change was based on the assumption from internal documentation that the log driver configuration was non-blocking. This change was fully reviewed according to our internal processes, was fully tested and was live weeks before the incident.
On October 1, a Klarna team changed the log-forwarder as part of an effort to gather more information. Specifically, the team added metrics to measure the size as well as cardinality of logs flowing through the log-forwarder. This change was fully reviewed and load tested. Once in production, performance degraded only after being live for over four hours.
The combination of these three changes led to the severe degradation of Klarna’s services primarily in Europe. While we designed our systems to prioritize availability over log delivery in such scenarios, the changes above caused us to inadvertently drift from this design.
Remediations
We have numerous safeguards in place to protect against disturbances in our systems. Even so, keeping these safeguards strong requires continuous improvement and optimization. We have identified areas of improvement, and already implemented mitigating actions, that reduce the risk and impact of similar incidents in the future.
The blocking behavior has been removed. We have done a full end-to-end analysis and configured systems to buffer to appropriate levels before dropping logs. This has already been rolled out to our most critical services and we aim to complete it across the entire company by October 15.
We’ve made a thorough analysis of why the change to the `blocking` log driver was written, reviewed and released. We now automatically validate this setting so that this configuration cannot be set incorrectly. We also have a detailed, contextual comment above this code to explain why. We believe that if such a comment had existed in the previous code the likelihood of misinterpretation would have been significantly reduced.
Since the log-forwarder does not get overloaded by CPU or memory, the standard metrics for resource starvation do not trigger alerts for this specific application, requiring us to implement custom alerting logic. This incident demonstrated that the logic we implemented was not complete and thus made our alerting insufficient. Upon further investigation we have corrected the specific alert as well as identified other metrics which will now alert if we see similar symptoms in the future.
Future Work
We have further identified several additional improvement areas that we will work on in the coming weeks and months, including:
Refining our log-forwarder setup.
Automatic testing of log-forwarder failure scenarios in the runtime platform by introducing simulated failures.
Improving our procedures for responding to large scale failures where the root cause is not apparent.
While we regret this issue ever occurred, we will do everything we can to learn from this experience and work tirelessly to regain our customers’ trust.